大家写代码的时候,是不是大部分时间都费在了各种神奇的问题上
各种突然
各种抽风
各种莫名其妙
各种小错误
我的看法
刚入门的时候非常正常,但如果已经在某个领域做了一段时间还一直维持这种状态那就有问题了。这很可能是所谓的撞大运/散弹枪编程的兆头。每次摆平某种抽风以后,务必总结问题和教训,做到下次从根本上防止再出现,能把你的代码写到让同事碰不到同样的问题更好(抽象、断言式编程/早崩溃、lint等等各种手段)
反正我现在更多时间都花在吐槽同事的代码上,有机会面对全新领域的时候才有机会遇到所谓的抽风,莫名其妙,遇到的时候我也只有兴奋,没有无奈
做服务器端开发需要具备什么样的基础知识?
最近转服务端开发了,但是对知识的补充还是有些茫然,我个人列出一些需要补充和学习的知识,如下:
- 基本的网络知识(TCP/IP , UDP , Socket等等)
- 网络操作系统 Linux,有时候需要配置运行环境
- 开发技术:php , python , 破儿(perl), java(公司需要), nodejs
- 相关技术的积累:memcache , redis , mongodb
- 数据库..
我列举的可能有的是多余的,也有遗漏的,请问各位有何看法? 还有网络的基础知识是否需要更佳深入的学习,比如七层模型,子网掩码的分配计算等等
我的看法
我觉得软件开发这个行当是工程性很强的一个行当,这类行当的学习路径和学术研究性的几乎相反:不是先学了一堆“基础知识” “背景知识” 之类的东西再深入研究,而是先从最高级最方便的quick&dirty way开始,向底层细化。
按我说就先挑一门语言,然后选这门语言的前三流行的框架或开源应用中任意一款,先撸个hello world,再撸个博客出来,博客做完发布做评论,做完评论做用户,做完用户再看看你以前写的代码删光从头写起。当然把博客换成其他需求也行,只要自己需要用的都行
至于需要的知识,压力大了自然要缓存,模块复杂了自然要解耦,上线次数多了自然要部署要自动化,一切知识都是以解决问题为导向的。没遇到问题就空学所谓基础知识,在我看来事倍功半。就好比题主提的“服务端开发”,其中也有很多细分,做业务逻辑的,高并发的,事务的,更别说做数挖的dba的devop的等等,又或是小业务的一条龙包干,都是相当不同的技能要求。
Backbone model设计
正在做一个对model增删改查的简单demo以学习backbone,现在的问题是model的表单不固定,需要根据model的类型动态变化。
比如,添加一个人员,普通属性如 名称 邮箱 地址 都是通用的,但是当用户选择了行业(医疗、教育)等,表单需要根据这个类型进行调整。
这种情况最简单的办法创建一个Person Model,把所有类型涉及到的attributes都塞到这里面,一个PersonFormView,绑定这个model,但select(行业)选择变化的时候,更新这个PersonFormView,这样的问题是:
- Person放了太多不该放东西
- view的render方法需要大量的if else逻辑用来判断类型
- 如果行业选择增多比如10个以上就egg pain了
按照普通的设计思路,普通用户Person应该作为基类,医疗用户,教育用户作为子类继承Person,View也类似,不同的子类负责不同的渲染。
但是感觉这样子渲染的时候没思路,怎么破?
我的看法
首先整理问题,其实有两个问题:Model复杂(乃至嵌套)和View复杂(乃至嵌套)
分开探讨
Model问题
“对象部分字段结构随某个类型字段变化而变化”是个常见的需求,这种情况下,问题很可能已经超出backbone的范围,需要和后端程序、以及DB存储结构共通考虑。通常同步后端的设计思路设计Model是比较安全简便的方法。
一般而言常见的解决方案有
A. 单表,字段包涵每个类型可能的全部所需字段,当类型不需要某个字段时该字段留空值
这是最快最简单的方法,风险题主也提到了,类型增多,又或者是差异变大时比较痛苦,另外“不同类型的不同字段验证逻辑不同”也会造成痛苦
如果类型不多,类型间字段差异不大时,可以选择这种方案,此时Backbone这层的Model不需要额外技术,照做即可
B. 拆表,主表含共通字段和类型,类型相关的字段放在子表/扩展表中,每个类型一张不同的扩展表
这是扩展性最强的方法,和前一个方法恰好相反,类型少,差异不大的时候比较痛苦,而做类似“不同类型字段验证逻辑不通”之类的事情水到渠成。
此时最应该有所谓的sub-model机制来对应后台的数据结构,在parse或者initialize的时候动手脚都应该可以实现,我没有具体实践过,建议搜索 backbone nested model看看别人的做法
C. 单表,一个“扩展字段”用类似JSON字符串的形式摆放所有的类型相关的数据,又或者是MongoDB类的文档数据库,直接一个字段搞定
这是前面两者的中间方案,也是最安全最不容易出大问题的,也是“罪孽”最深重的——复合字段,扩展字段是魔鬼!随着项目的迭代,它们理论上应该渐渐被修改为前两种方案,而实际上往往成了垃圾场,所有人都把东西往这儿一扔,更糟糕的是你还经常需要里面的东西,甚至对里面的内容筛选搜索
但如果上述糟糕的事情没有发生,那么扩展字段是最有弹力的做法,此时backbone的model里面可以同样使扩展字段是复合值,复刻后台的数据结构,也可以用sub-model来描述扩展字段,加强结构性
View的问题
实现的方式大致还是划分成拆不拆子View
A. 拆子View(注意不是继承)
子View的实现有很多 backbone.layoutmanager基本专门做这个,其他几乎所有基于Backbone的框架都会涉及这一块,本质就是父View管理子View的创建、销毁,子View通过某种形式和父View通信(建议向上用事件冒泡,向下用方法调用)
此时,每个类型特殊的字段对应一个子View,父View根据不同类型创建不同的子View插入合适位置,在类型变换的时候销毁原有的子View重新创建
B. 不拆子View
不拆子View的最大问题就是渲染复杂,其次是数据收集复杂,这里建议用模版渲染来解决这个问题,关于这个方案建议参考我之前写的组织大表单应用中javascript代码的一种方法 后半部分,这里贴一下示意图
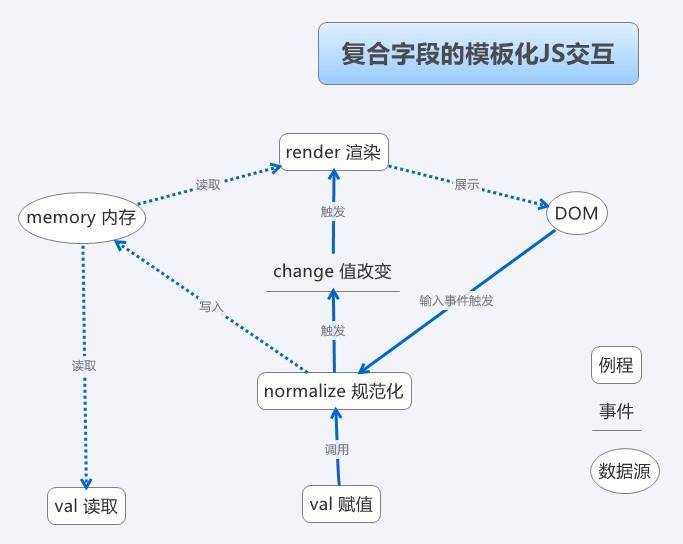
无论如何,大量if确实是需要避免的,核心思路就是根据不同类型选择不同的{子View,子模版}
最后,不建议选择类型作为子类继承父类,详细请搜索“组合优于继承”,这里不同行业的人从领域模型的角度来说或许是“医生” is-a “人”,但实现的时候用继承会很糟糕,比如再来个需要根据不同户口类型填不同的信息之类,直接傻眼。 更合适的拆分是“人” has-a “行业信息”,“医疗行业信息” is-a “行业信息”
这是我在 SegmentFault 上的问题回答选编,遵循CC BY-SA 3.0 CN 分享
题图:万智【霰散弹】
